
DeepSeek LLM-V2: Next Generation AI Capabilities
Exploring the revolutionary features of DeepSeek’s latest large language model that’s pushing the boundaries of AI performance
🧠 Hybrid Thinking Mode
A single unified model that supports both “think” and “non-think” modes, eliminating the need for separate reasoning models. This dual capability allows the AI to switch between detailed step-by-step reasoning and direct responses based on the task requirements.
📚 Extended Context Window
Massive 128K token capacity equivalent to processing a complete 300-page book in a single conversation. This extended context enables deeper analysis of lengthy documents and more coherent long-form interactions.
🎯 Reduced Hallucinations
A remarkable 38% decrease in factual errors compared to previous DeepSeek models through advanced training techniques. This significant improvement enhances reliability for critical applications requiring factual accuracy.
⚡ Enhanced Reasoning Power
43% improvement in multi-step reasoning capabilities for complex problem-solving across mathematics, coding, and scientific analysis. This advancement enables the model to tackle more sophisticated challenges with greater precision.
🌐 Global Language Support
Near-native proficiency across 100+ languages with significantly improved Asian and low-resource language capabilities. This expanded linguistic range makes the model more accessible and effective for global users.
🔧 Massive Scale Architecture
671B total parameters with 37B activated parameters, optimized for efficient performance. This innovative architecture delivers state-of-the-art capabilities while maintaining practical computational requirements.
Revolutionary Hybrid Intelligence Takes Center Stage
DeepSeek V3.1 just dropped on August 21, 2025, and it’s causing seismic shifts across the AI industry. This isn’t just another model update—it’s a complete reimagining of how AI systems should work, think, and interact with the world around them.
Chinese startup DeepSeek has created something remarkable: an AI model that can literally switch between thinking deeply about complex problems and responding instantly for simple tasks. All within the same system, all controlled by a simple toggle button.
The implications are staggering. While tech giants pour billions into AI development, DeepSeek has achieved comparable performance for a fraction of the cost, challenging everything we thought we knew about AI economics.
Two Brains, One Extraordinary Model
Think Mode: The Deep Reasoning Powerhouse
DeepSeek V3.1’s Think mode activates advanced chain-of-thought reasoning that rivals OpenAI’s premium models. When you need the AI to solve complex mathematical problems, debug intricate code, or analyze multi-layered business scenarios, Think mode delivers deliberate, step-by-step reasoning.
The model breaks down complex problems into manageable chunks, showing its work like a brilliant student walking through calculus equations. This transparency helps users understand not just the answer, but the logical pathway that led there.
Key Think Mode Capabilities:
- 📌 Advanced mathematical problem-solving (93.1% pass rate on AIME 2024)
- 📌 Complex coding tasks with debugging explanations
- 📌 Multi-step agent workflows for business automation
- 📌 Research analysis requiring deep contextual understanding
Non-Think Mode: Lightning-Fast Responses
For everyday interactions, translations, simple questions, or quick content generation, Non-Think mode provides instant responses without the computational overhead of deep reasoning. This mode handles the majority of typical AI interactions with remarkable speed and efficiency.
Users can toggle between modes instantly using the “DeepThink” button on chat.deepseek.com, making it incredibly user-friendly for different types of tasks throughout the day.
Technical Architecture That Changes Everything

Massive Scale with Smart Activation
DeepSeek V3.1 operates on a Mixture-of-Experts (MoE) architecture with approximately 685 billion parameters. However, it only activates 37 billion parameters per token, keeping computational costs remarkably low while maintaining frontier-level performance.
This selective activation means you get the power of a massive model without the massive computational bill. It’s like having access to a supercomputer that only uses the processing power you actually need for each specific task.
Extended Context Window Revolution
The model features a 128,000-token context window—enough to process entire research papers, lengthy codebases, or extended business documents in a single conversation. This extended memory allows for more coherent, contextually aware interactions across long sessions.
Context Window Comparison:
- 📌 DeepSeek V3.1: 128,000 tokens
- 📌 GPT-5: 272,000 tokens
- 📌 Claude 4.1: 200,000 tokens
- 📌 Previous DeepSeek models: 64,000 tokens
Advanced Agent Capabilities
Post-training optimizations have significantly enhanced the model’s ability to use tools, perform multi-step workflows, and act as an autonomous agent. The model excels at:
🔍 Search Agent Tasks:
- Web browsing and information gathering
- Complex research workflows
- Real-time data analysis and reporting
⚙️ Code Agent Functions:
- Automated debugging and code review
- Multi-file project analysis
- Software engineering task automation
🤖 Business Process Automation:
- Document analysis and summarization
- Customer service workflow management
- Data processing and report generation
Cost Revolution That’s Shaking Silicon Valley

Pricing That Defies Industry Standards
Starting September 5, 2025, DeepSeek V3.1 API pricing will be:
- Input tokens (cache hit): $0.07 per million tokens ($0.000007 per 1K tokens)
- Input tokens (cache miss): $0.56 per million tokens ($0.00056 per 1K tokens)
- Output tokens: $1.68 per million tokens ($0.00168 per 1K tokens)
Competitor Pricing Comparison:
| Model | Output Price (per million tokens) | Cost Difference |
|---|---|---|
| DeepSeek V3.1 | $1.68 | Baseline |
| GPT-5 | $10.00 | 495% higher |
| Gemini 2.5 Pro | $10.00-$15.00 | 495-792% higher |
| Claude Opus 4.1 | Up to $75.00 | 4,364% higher |
Training Cost Breakthrough
DeepSeek V3.1’s development showcases unprecedented efficiency in AI training. The base V3 model cost approximately $5.6 million to train—compared to hundreds of millions spent by competitors. This includes:
- Pre-training: 2.664 million H800 GPU hours
- Context extension: 119,000 GPU hours
- Post-training: 5,000 GPU hours
- Total: 2.788 million GPU hours at $2 per hour
This efficiency stems from innovative architectural choices, optimized training pipelines, and strategic use of available hardware despite US chip export restrictions.
Performance Benchmarks That Speak Volumes
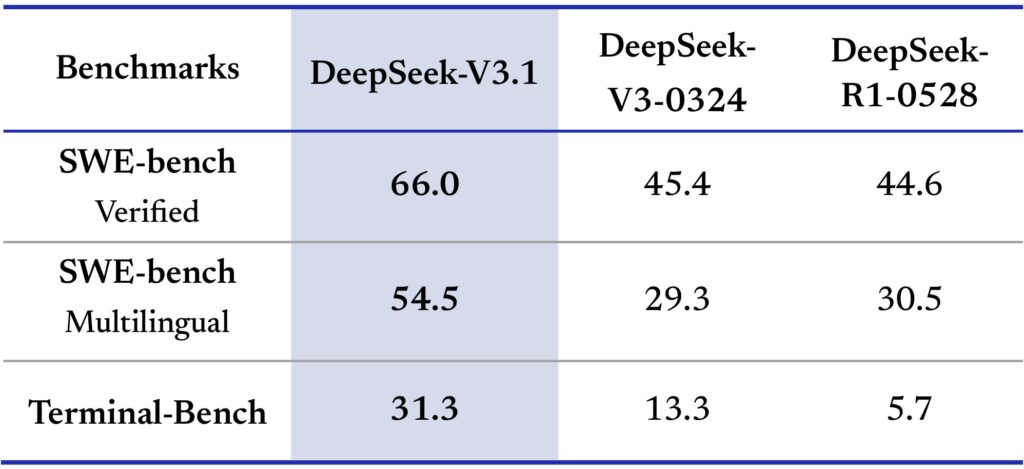
Programming Excellence
DeepSeek V3.1 achieved a remarkable 71.6% score on the Aider programming benchmark, outperforming Claude Opus 4 while costing 98% less per task. The model demonstrates exceptional capabilities in:
- ✅ Code generation across multiple programming languages
- ✅ Debugging complex software issues
- ✅ Code review and optimization suggestions
- ✅ Multi-file project understanding
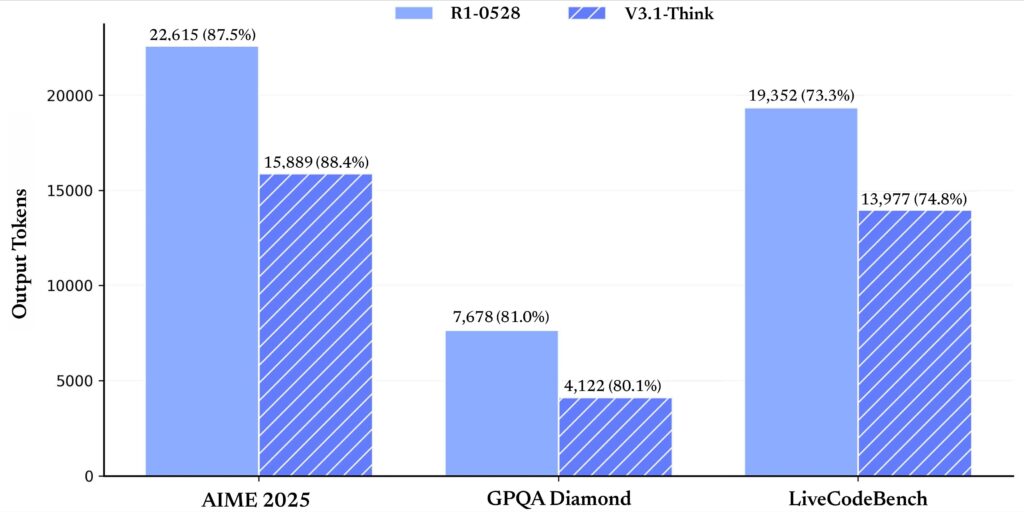
Mathematical and Reasoning Prowess
The model showcases impressive performance across challenging mathematical benchmarks:
AIME 2024: 93.1% pass rate in Think mode (66.3% in Non-Think mode)
MATH-500: Strong performance in advanced mathematical problem-solving
MMLU-Redux: 93.7% in Think mode, demonstrating broad knowledge application
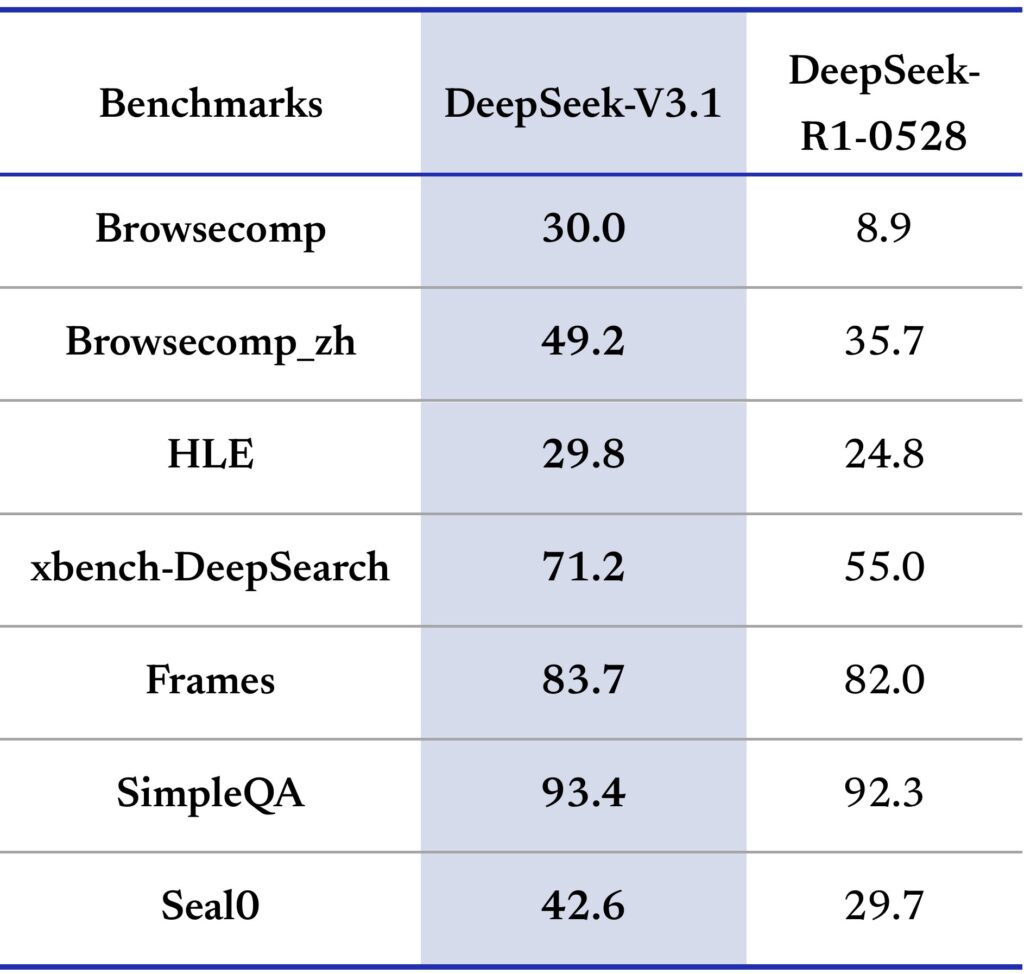
Real-World Problem Solving
Community tests reveal DeepSeek V3.1’s ability to handle complex physics simulations, logical puzzles, and multi-step reasoning tasks that previously challenged even premium AI models.
The Company Behind the Innovation
High-Flyer Capital’s AI Vision
DeepSeek emerged from High-Flyer Capital, a quantitative hedge fund founded by Liang Wenfeng in 2015. The fund’s background in algorithmic trading and data analysis provided the perfect foundation for AI model development.
Liang Wenfeng, who serves as CEO of both companies, transitioned High-Flyer’s AI research capabilities into DeepSeek as an independent entity in July 2023. This unique origin story explains DeepSeek’s focus on efficiency and practical applications rather than pure research.
Unconventional Company Culture
Unlike typical Chinese tech companies with their demanding “996” work culture, DeepSeek fosters a merit-based environment that prioritizes technical competence over work experience. The company actively recruits:
- Recent university graduates with strong technical foundations
- Researchers from diverse academic backgrounds
- Developers focused on innovation rather than traditional hierarchies
This approach has created a culture of curiosity-driven innovation that encourages breakthrough thinking rather than incremental improvements.
Open Source Strategy That’s Changing the Game
MIT License Accessibility
DeepSeek V3.1 is released under the MIT license for its source code, making it one of the most permissive AI licenses available. This means:
Commercial Freedom:
- ✅ Use in commercial products without royalty payments
- ✅ Modify and distribute derivative works
- ✅ Integrate into proprietary systems
- ✅ Build services and platforms around the model
Developer Benefits:
- ✅ Full access to model weights and configurations
- ✅ Ability to fine-tune for specific use cases
- ✅ Community-driven improvements and innovations
- ✅ Reduced vendor lock-in compared to proprietary alternatives
Model Licensing Considerations
While the source code uses MIT licensing, the trained models themselves use a custom DeepSeek license that includes some use-based restrictions. This hybrid approach aims to balance openness with responsible AI deployment.
Business Applications Transforming Industries
Enterprise Workflow Automation
DeepSeek V3.1’s agent capabilities are revolutionizing how businesses handle routine tasks:
📊 Document Processing:
- Automated contract analysis and review
- Financial report generation and analysis
- Legal document summarization
- Compliance monitoring and reporting
🎯 Customer Service Enhancement:
- 24/7 intelligent chatbot support
- Multilingual customer interaction handling
- Sentiment analysis and response optimization
- Automated ticket routing and prioritization
Industry-Specific Solutions
Finance and Banking:
- Risk modeling and fraud detection systems
- Real-time market analysis and reporting
- Automated compliance checking
- Customer credit assessment automation
Healthcare and Medical:
- Medical record processing and analysis
- Diagnostic assistance and pattern recognition
- Patient communication automation
- Research paper analysis and summarization
Manufacturing and Supply Chain:
- Predictive maintenance scheduling
- Supply chain optimization algorithms
- Quality control automation
- Production planning and forecasting
Technical Implementation and Integration
API Access and Development
DeepSeek V3.1 offers two primary API endpoints:
- deepseek-chat: For Non-Think mode interactions
- deepseek-reasoner: For Think mode reasoning tasks
Both endpoints support:
- 🔌 Anthropic API format compatibility
- 🔌 Strict function calling in beta
- 🔌 128K context window for extended conversations
- 🔌 Multiple precision formats (BF16, F8_E4M3, F32)
Hardware Optimization
The model supports deployment across various hardware configurations, making it accessible to organizations with different infrastructure capabilities. This flexibility contrasts sharply with models that require specific, expensive hardware setups.
Global Impact and Industry Disruption
Market Response and Stock Impact
DeepSeek’s breakthrough triggered massive market reactions, with tech stocks losing over $1 trillion in value as investors reassessed AI company valuations. The model’s success demonstrated that technological leadership doesn’t require the largest budgets—it requires the smartest approaches.
Geopolitical Implications
The model’s development using restricted hardware (H800 chips instead of the more powerful H100s) showcases innovative engineering under constraints. This achievement has profound implications for:
Technology Policy:
- Effectiveness of export controls on AI development
- Alternative pathways to AI advancement
- Open-source vs proprietary development strategies
Competitive Landscape:
- Challenge to US dominance in frontier AI models
- New benchmarks for cost-effective AI development
- Acceleration of global AI democratization
Future Implications and What’s Next
The Agent Era Beginning
DeepSeek positions V3.1 as the “first step toward the agent era”—AI systems that can autonomously handle complex, multi-step tasks across various domains. This shift from simple question-answering to autonomous task execution represents a fundamental evolution in AI capabilities.
Ecosystem Development
The open-source nature of DeepSeek V3.1 is likely to spawn numerous derivative projects, fine-tuned versions, and specialized applications. This ecosystem effect could accelerate AI innovation in ways that proprietary models cannot match.
Industry Standard Setting
With its combination of high performance and low cost, DeepSeek V3.1 is establishing new expectations for AI model economics. Competitors will need to either match these cost efficiencies or demonstrate significantly superior capabilities to justify higher pricing.
Strategic Advantages That Matter
For Businesses and Developers
Cost Efficiency: Deploy frontier AI capabilities without breaking budgets
Flexibility: Switch between reasoning modes based on task requirements
Customization: Modify and optimize models for specific use cases
Independence: Reduce reliance on expensive proprietary AI services
For Content Creators and Marketers
Content Generation: Create high-quality content across multiple languages
SEO Optimization: Generate keyword-rich content with natural integration
Video Script Writing: Develop engaging scripts for YouTube and social media
Research Automation: Gather and analyze information for content planning
Making AI Work Smarter, Not Harder
DeepSeek V3.1 represents more than just another AI model release—it’s a fundamental shift toward intelligent, efficient, and accessible artificial intelligence. By combining cutting-edge capabilities with practical economics, DeepSeek has created a model that democratizes access to frontier AI technology.
The hybrid Think/Non-Think architecture acknowledges that different tasks require different levels of computational intensity. This nuanced approach to AI processing could become the new standard for how intelligent systems operate across industries.
Whether you’re a startup looking to integrate AI capabilities, an enterprise seeking cost-effective automation solutions, or a developer wanting to build the next generation of intelligent applications, DeepSeek V3.1 offers a compelling combination of performance, flexibility, and affordability that’s reshaping the AI landscape.
As we move deeper into 2025, DeepSeek V3.1 stands as proof that innovation, efficiency, and accessibility can coexist in AI development—setting the stage for a more diverse, competitive, and ultimately beneficial AI ecosystem for everyone.







