
Google’s File Search: Revolutionizing RAG Implementation
Transform your retrieval-augmented generation workflow with Google’s powerful File Search tool that simplifies development and enhances performance.
Complete End-to-End Automation
Google’s File Search tool fully automates the entire RAG pipeline (chunking, embedding, and vector indexing) that previously required significant manual engineering. This comprehensive automation eliminates technical complexity and streamlines implementation.
Simplified 3-Step Implementation
Create store → Upload file → Query data – reducing RAG setup from weeks to minutes with minimal code. This straightforward approach allows developers of all skill levels to implement sophisticated RAG systems without extensive specialized knowledge.
Real-Time Semantic Search with Source Citations
Provides accurate information retrieval with transparent source references for enhanced reliability. Every result includes precise citations to original documents, ensuring accountability and enabling verification of all generated content.
10X Faster Development Cycle
Eliminates complex infrastructure management, allowing developers to focus on application logic instead of RAG engineering. This dramatic acceleration in development time means products can reach market faster and teams can iterate more rapidly.
Scalable Performance
Handles large datasets with exceptionally low latency without requiring additional infrastructure management. The system maintains high performance even as your data volumes grow, with Google’s infrastructure automatically scaling to meet demand.
Cost-Efficient Solution
Reduces both development time and operational costs compared to building custom RAG systems from scratch. By eliminating the need for specialized engineering talent and complex infrastructure, organizations can achieve sophisticated RAG capabilities at a fraction of the traditional cost.
Why Google Just Changed the Way AI Reads Your Documents
Think about the last time you needed specific information from a massive PDF report or dozens of company documents. You probably spent ages scrolling, searching for keywords, and still might have missed what you were looking for. Google just announced something that could change this experience entirely.
On November 6, 2025, Google launched the File Search Tool in the Gemini API—a fully managed system that lets AI understand and retrieve information from your files in seconds. This isn't just another search feature. It's what developers call Retrieval-Augmented Generation (RAG), but instead of building it yourself with countless tools and configurations, Google handles everything behind the scenes.
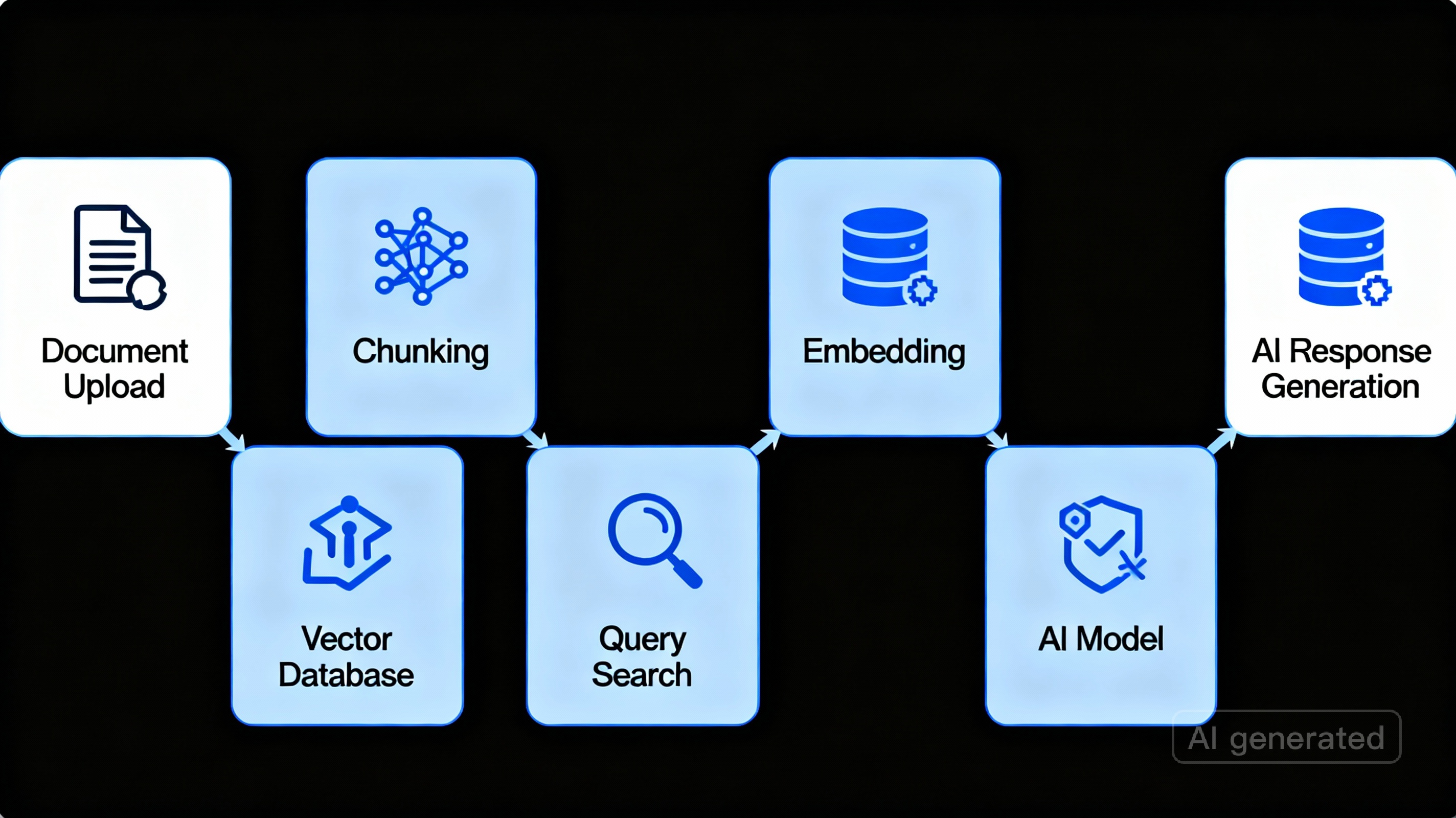
From Complex Engineering Headaches to Simple API Calls

Building RAG systems traditionally feels like assembling furniture without instructions. You need to set up file storage, choose chunking strategies, configure embedding models, manage vector databases, and then figure out how to connect everything together. For many developers, this process takes weeks.
The File Search Tool flips this script. Instead of managing five different services, you upload your files and start asking questions. That's it. The entire pipeline—from storage to embeddings to retrieval—runs automatically within the existing generateContent API that developers already know.
Here's what happens automatically when you use File Search:
📌 Intelligent file storage that keeps your documents organized and secure
📌 Smart chunking that breaks documents into meaningful segments
📌 Embedding generation using Google's latest Gemini Embedding model
📌 Vector database management for lightning-fast searches
📌 Context injection that feeds relevant information directly to the AI
Traditional RAG setups require constant maintenance. You're juggling storage costs, optimizing chunk sizes, monitoring vector database performance, and debugging connection issues. File Search eliminates these headaches. The system automatically applies optimal chunking strategies and handles all the infrastructure complexity.
Understanding How Semantic Search Actually Works
Remember when search engines only found pages with your exact keywords? Modern AI search works completely differently, and understanding this difference matters.

When you upload a document to File Search, the system doesn't just index words. It converts your text into mathematical representations called embeddings—think of them as coordinates in a vast multidimensional space where similar concepts cluster together naturally.
If your document mentions "automobile," and someone asks about "vehicles," the system connects these concepts even though the exact word wasn't used. This happens because both terms share similar meanings and context, placing their embeddings close together in vector space.
The Gemini Embedding model powering this system recently topped the Massive Text Embedding Benchmark (MTEB), which tests embedding quality across 250+ languages and over 100 different tasks. This means File Search doesn't just work well in English—it understands context and meaning across dozens of languages.
When you make a query, File Search converts your question into an embedding, calculates similarity scores against all document chunks in your store, and retrieves the most relevant pieces. This entire process happens in milliseconds, even when searching through thousands of documents.
Three Simple Steps That Replace Weeks of Development
Setting up File Search takes minutes, not days. The process follows three straightforward stages that hide enormous complexity underneath.
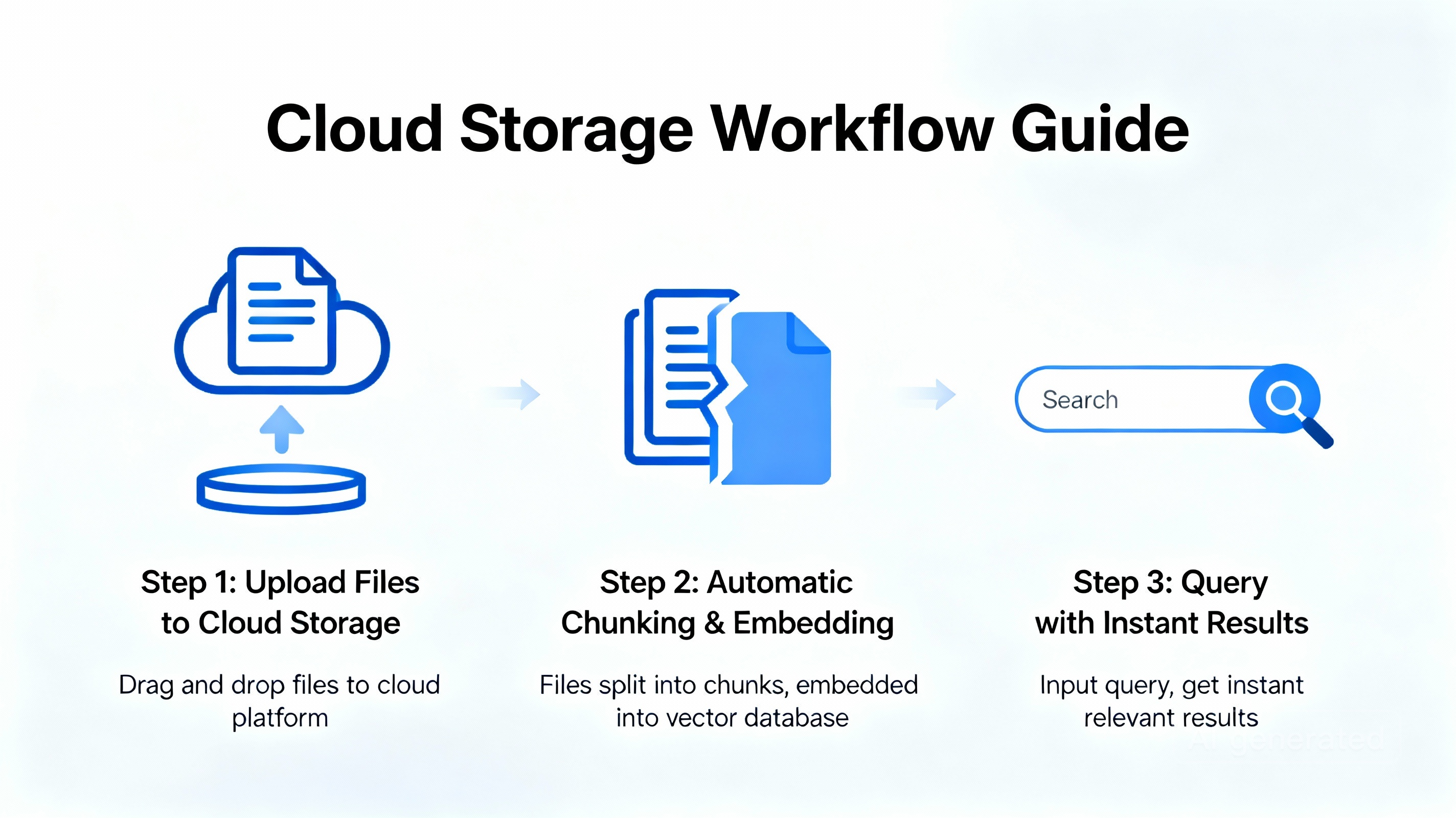
Stage One: Create Your File Search Store
A file search store acts as a container for all your processed documents. Unlike raw files uploaded through standard APIs (which delete after 48 hours), content imported into a file search store stays permanently until you manually remove it. You can create multiple stores to organize documents by project, department, or topic.
Creating a store takes one line of code. You can add an optional display name to keep things organized, especially when managing multiple projects.
Stage Two: Upload and Index Your Documents
You have two options here. You can either upload files directly to your file search store using uploadToFileSearchStore, or upload them separately and then import them. Both methods work well—choose based on your workflow.
During this stage, magic happens automatically. The system chunks your document intelligently, generates embeddings using the Gemini Embedding model (gemini-embedding-001), and indexes everything for fast retrieval. The temporary file reference gets deleted after 48 hours, but the processed, searchable data remains in your store indefinitely.
If you need more control, you can customize the chunking strategy. Set maximum tokens per chunk and overlap tokens to fine-tune how documents get divided. Most developers find the automatic settings work excellently, but this flexibility helps when working with specialized document types.
Stage Three: Query Your Documents
Now the real power shows up. Instead of manually searching through files, you ask questions in natural language. The File Search tool automatically determines if it needs external knowledge to answer. If yes, it generates optimized search queries, retrieves relevant chunks from your store, and uses this context to generate accurate, grounded responses.
The model even includes built-in citations that show exactly which parts of your documents were used to create each answer. This citation feature becomes incredibly valuable for fact-checking and verification, especially in fields like legal research, medical information, or financial analysis where accuracy matters tremendously.
Breaking Down the Pricing That Actually Makes Sense
Traditional RAG systems drain budgets in unexpected ways. You pay for vector database hosting, storage costs, compute time for generating embeddings, and ongoing maintenance. These costs add up quickly and scale unpredictably.

Google structured File Search pricing to be both transparent and affordable. Here's the complete breakdown:
➡️ Indexing time embeddings: $0.15 per 1 million tokens (₹12.48 per 1 million tokens)
➡️ Storage: Free of charge
➡️ Query time embeddings: Free of charge
➡️ Retrieved document tokens: Charged as regular context tokens
You only pay once when first indexing your files. After that, storage costs nothing, and generating embeddings for queries costs nothing. This pricing model makes costs predictable and significantly cheaper than managing your own infrastructure.
For storage capacity, Google offers tiered limits:
✅ Free tier: 1 GB of total file search store space
✅ Tier 1: 10 GB
✅ Tier 2: 100 GB
✅ Tier 3: 1 TB (1,000 GB)
Individual files can be up to 100 MB each. Google recommends keeping each file search store under 20 GB for optimal retrieval speed, though you can create multiple stores if needed.
Which Files Can You Actually Use With This Tool
File Search supports an impressively wide range of formats. Whether you're working with business documents, code files, or technical specifications, chances are your format works.
Business and Document Formats:
The tool handles standard office documents including PDF, DOCX (Microsoft Word), DOC (older Word format), XLSX (Excel spreadsheets), XLS (older Excel), PPTX (PowerPoint presentations), and ODT (OpenDocument text). If your company uses typical business file formats, you're covered.
Programming and Development Files:
Developers can upload code in virtually any language. Supported formats include Python, JavaScript, TypeScript, Java, C, C++, C#, Go, Rust, Ruby, PHP, Swift, Kotlin, Scala, Dart, Lua, R, and many others. The system also handles JSON, XML, YAML, SQL, Bash scripts, PowerShell scripts, and Shell scripts.
Text and Markup Formats:
Plain text (TXT), Markdown, HTML, CSS, RTF, CSV (comma-separated values), TSV (tab-separated values), and LaTeX files all work seamlessly. This covers everything from simple notes to technical documentation.
Specialized Technical Formats:
The system even supports niche formats like Jupyter notebooks, Cassandra, CUDA, Haskell, Lisp, Pascal, and dozens of other specialized file types used in scientific computing, data analysis, and technical research.
This comprehensive format support means you rarely need to convert files. Upload your existing documents and start searching immediately.
Real Companies Already Seeing Remarkable Results
Beam, an AI-powered game generation platform developed by Phaser Studio, integrated File Search into their production workflow during the early access phase. Their experience shows what this tool can do at scale.
Beam's system maintains a library of over 3,000 files organized across six separate corpora (collections). These files include game templates, component libraries, design documentation, and Phaser.js technical knowledge. Before File Search, finding the right code snippet or design pattern meant hours of manual cross-referencing across multiple documents.
Now, File Search runs thousands of queries daily against this entire library. The system handles parallel searches across all six corpora simultaneously, combining results in under 2 seconds. Tasks that previously took days to prototype now become playable game concepts in minutes.
Richard Davey, CTO of Phaser Studio, explained their results: "File Search allows us to instantly surface the right material, whether that's a code snippet for bullet patterns, genre templates or architectural guidance from our Phaser 'brain' corpus."
This speed improvement didn't require Beam to build custom infrastructure or hire specialized engineers. They simply integrated File Search into their existing Gemini API workflow.
Comparing Google's Approach to Other RAG Solutions
The managed RAG market includes several major players. OpenAI offers file search through their Assistants API. AWS and Microsoft provide enterprise RAG frameworks. Open-source options like LlamaIndex, LangChain, and Haystack give developers complete control.
Each approach has trade-offs. Self-hosted solutions offer maximum flexibility but require significant engineering resources. You control every detail, but you also manage every component, handle scaling challenges, and debug complex integration issues.
OpenAI's Assistants API provides similar managed functionality, but developers report slower response times. Community feedback suggests Google's Gemini-based File Search delivers noticeably faster results, particularly when using Gemini 2.0 Flash models.
Enterprise platforms from AWS and Microsoft integrate deeply with their respective cloud ecosystems. If your company already runs entirely on Azure or AWS, those solutions might integrate more smoothly with existing infrastructure. However, they typically require more initial configuration and ongoing orchestration compared to Google's approach.
Google's File Search stands out by requiring minimal orchestration while functioning independently. You don't need to coordinate multiple services or configure complex pipelines. The tool works within your existing Gemini API calls, making integration straightforward for developers already familiar with the API.
The cost model also differs significantly. Many RAG platforms charge for storage, query processing, and data retrieval separately. File Search bundles most of these costs, charging primarily for initial indexing while making storage and query-time embeddings free.
Understanding Both the Power and the Limitations
File Search excels at specific use cases while having clear boundaries developers should understand.
Where File Search Shines:
👉 Customer support systems that need to retrieve specific information from product documentation
👉 Internal knowledge bases where employees ask questions about company policies, procedures, or technical specifications
👉 Legal research requiring quick access to case law, contracts, and regulatory documents with accurate citations
👉 Educational platforms that help students find relevant information from textbooks and study materials
👉 Content discovery systems that surface relevant articles, research papers, or creative assets
The citation feature makes File Search particularly valuable in regulated industries. When the AI explains something, it shows exactly which documents and passages it used. This transparency supports compliance requirements in healthcare, finance, and legal fields where you must verify information sources.
Current Limitations to Consider:
⛔️ File size caps at 100 MB per document, which might not work for extremely large datasets
⛔️ Optimal performance happens when individual file search stores stay under 20 GB
⛔️ Best suited for text-based retrieval rather than complex multi-modal queries combining images, audio, and text
⛔️ Requires structured documents to work well—highly unstructured or poorly formatted content may not chunk effectively
File Search works as a retrieval tool, not a general-purpose AI system. It finds and surfaces relevant information but doesn't reason through multi-step tasks, make complex decisions, or integrate real-time operational data the way more advanced agentic systems do.
For projects requiring real-time data integration from APIs, strict regulatory compliance with deterministic accuracy, or sophisticated multi-hop reasoning across disconnected data sources, you might need to combine File Search with additional tools or consider more complex RAG architectures.
Privacy, Security, and Data Control Considerations
When uploading company documents or sensitive information to any cloud service, understanding data handling becomes critical.
Files uploaded to File Search stores remain under your control. The processed data—chunks, embeddings, and indexes—persists indefinitely until you explicitly delete it. This differs from temporary file storage through the standard Files API, where content disappears after 48 hours.
Google's Gemini API includes standard security measures, but your usage tier affects whether your data helps improve Google's products. The free tier allows Google to use your data for product improvement, while paid tiers explicitly do not. For businesses handling sensitive information, paid tiers provide stronger privacy guarantees.
You can organize documents across multiple file search stores to implement access control and separation. For example, create separate stores for different departments, security levels, or projects. This organization helps manage permissions and prevents unintended information mixing.
The metadata filtering feature adds another control layer. Tag documents with custom metadata (author, date, department, classification level), then restrict queries to only search within documents matching specific tags. This feature enables building systems where users only access information they're authorized to see.
For industries with strict compliance requirements—healthcare, finance, legal—thoroughly review Google's data processing terms and consider how File Search fits within your regulatory framework. The citation and traceability features help with audit requirements, but you remain responsible for ensuring your implementation meets industry-specific regulations.
Getting Started With File Search Right Now
You can start experimenting with File Search immediately through Google AI Studio or by using the Gemini API directly.
Google AI Studio provides a web-based interface where you can test File Search without writing code. The platform includes a template app called "Ask the Manual" that demonstrates the tool in action. You can upload your own documents, ask questions, and see how the system retrieves and cites information. This hands-on approach helps you understand capabilities before committing to development.
For developers ready to integrate File Search into applications, the Gemini API supports both Python and JavaScript/TypeScript through official SDKs. The documentation includes complete code examples showing how to create file search stores, upload documents, configure chunking strategies, and make queries.
A typical implementation workflow looks like this:
Step 1: Set up your Gemini API key and install the Google Generative AI SDK for your preferred language
Step 2: Create a file search store with a descriptive display name
Step 3: Upload your documents directly to the store or import previously uploaded files
Step 4: Make queries by calling generateContent with the file search tool configured
Step 5: Parse responses to extract both the generated text and citation information
The API reference documentation covers advanced features like custom metadata filtering, chunking configuration options, and managing multiple file search stores programmatically.
For developers working within the Google Cloud ecosystem, File Search integrates with Vertex AI, allowing unified billing and pipeline management alongside other Google Cloud services like BigQuery.
What This Means for the Future of AI-Powered Search
File Search represents a broader shift in how we build AI applications. Instead of developers becoming experts in vector databases, embedding models, and retrieval optimization, they focus on solving actual business problems while managed services handle infrastructure complexity.
This democratization of RAG technology lets smaller teams and independent developers build sophisticated AI features that previously required extensive resources. A solo developer can now create a customer support chatbot that accurately answers questions from thousands of pages of documentation—something that would have required a team of engineers just a year ago.
The trend toward managed AI services will likely accelerate. Just as cloud computing freed developers from managing physical servers, managed RAG systems free them from managing complex AI infrastructure. This evolution lets innovation happen faster and makes advanced AI capabilities accessible to more people.
Google's pricing model—free storage, free query-time embeddings, and pay-once indexing—might pressure competitors to reconsider their cost structures. If managed RAG becomes both easier and cheaper than self-hosting, adoption will accelerate dramatically.
We're also seeing AI systems become more verifiable and transparent. Built-in citations aren't just a nice feature—they're becoming essential for trust and accountability. As AI makes its way into more critical decisions (medical advice, legal research, financial planning), being able to trace information back to source documents becomes non-negotiable.
The next frontier likely involves combining retrieval systems like File Search with more sophisticated reasoning capabilities. Imagine systems that not only find relevant information but also synthesize insights across multiple documents, identify contradictions, track how information changes over time, and proactively suggest connections you might not have considered.
Wrapping Up the File Search Story
Google's File Search Tool in the Gemini API solves a real problem that's been frustrating developers for years. Building RAG systems shouldn't require weeks of setup and ongoing infrastructure management. By handling chunking, embeddings, storage, and retrieval automatically, File Search lets developers focus on building features instead of managing pipelines.
The combination of comprehensive file format support, transparent pricing, built-in citations, and impressive performance makes this tool immediately useful for a wide range of applications. Whether you're building customer support systems, internal knowledge bases, research tools, or content discovery platforms, File Search provides the retrieval capabilities you need without the usual complexity.
For developers already using the Gemini API, integration takes minutes. For teams evaluating RAG solutions, the managed approach offers significant advantages over self-hosted alternatives in terms of cost, maintenance, and time-to-market.
The early results from companies like Beam demonstrate that File Search works at scale in production environments. As more developers experiment with the tool and share their implementations, we'll likely see creative applications we haven't imagined yet.
The File Search Tool matters because it removes barriers. More people can now build AI applications that understand and retrieve information from documents accurately. That accessibility will drive innovation in ways we're just beginning to see.







